Uptime: Longer Data Center Outages Are Becoming More Common
Uptime is always the prime directive for data centers. As the world recovers from the COVID-19 pandemic, reliable digital infrastructure is more important than ever in keeping the economy connected.
So how are things going? The frequency of data center downtime hasn’t changed significantly, but outages are becoming longer and more expensive, according to new research from The Uptime Institute. The key findings:
- Prolonged downtime is becoming more common in publicly reported outages. The gap between the beginning of a major public outage and full recovery has stretched significantly over the last five years, with nearly 30% of these outages in 2021 lasted more than 24 hours, which Uptime characterized as “a disturbing increase” from just 8% in 2017.
- Downtime is also becoming more expensive, with more than 60% of failures resulting in at least $100,000 in total losses, up substantially from 39% in 2019. The share of outages that cost upwards of $1 million increased from 11% to 15% over that same period.
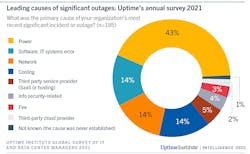
- In a trend we first highlighted last year, networking issues have become the single biggest cause of all IT service downtime incidents – regardless of severity – over the past three years. Uptime attributes this to “complexities from the increasing use of cloud technologies, software-defined architectures and hybrid, distributed architectures. “
- The most significant outages are usually tied to electrical equipment, especially uninterruptible power supply (UPS) failures. “Power-related outages account for 43% of outages that are classified as significant (causing downtime and financial loss),” said Uptime.
The survey is the latest annual survey from The Uptime Institute, whose data is notable because it highlights trends in data center outages that may not be publicly reported.
Online services are more important than ever in the wake of the COVID-19 pandemic, which has boosted reliance on remote work and learning – meaning that service outages are more broadly felt, and generate wider notice.
Lengthy Downtime Incidents Make Headlines
A new wrinkle is the growth of lengthier outages over the past two years. Some of these have been very public, such as a massive global outage at Meta last October that left Facebook, Instagram and WhatsApp offline for at least five hours. Facebook later said that a configuration error broke its connection to a key network backbone, disconnecting all of its data centers from the Internet and leaving its DNS servers unreachable.
Another example is the 73-hour outage last year at Roblox, which cost the metaverse company an estimated $25 million in lost bookings. In an incident report, Roblox said several software services contended for resources, making it harder to diagnose a bug in a database.
The Facebook and Roblox incidents illustrates how the growing complexity of online applications can sometimes make it harder to trouble-shoot automated infrastructure, leading to lengthier outages.
The growing role for network issues was seen in a major outage at Amazon Web Services in December, with the ripples spreading across the Internet to interrupt service for many popular web services that run their infrastructure on the AWS cloud. The issue was traced to problems with several network devices in the AWS data center cluster in Northern Virginia.
Power and equipment issues were prominent in another lengthy outage in 2021, when a data center fire at OVH in Strasbourg, France left many customers offline for days. The SBG2 data center was destroyed by fire on March 9, which required the power to be turned off for the entire four-building campus. A second data center building, SBG1, was eventually shuttered after a smoke incident in a UPS room.
The growing financial impact of outages is not a surprise, given how digital services have become central to nearly every business. The “cost of downtime” has long been used to underscore the value of data center services and maintenance, but now serves as a reflection of increased reliance on data infrastructure.
More Investment, Yet More Complexity
All of this is happening in a period of enormous investment in digital infrastructure, including huge growth for cloud platforms, record-setting M&A action and the creation of new operating platforms for data centers.
That investment doesn’t neatly translate into improved reliability, especially in a complex environment in which new architectures are spreading IT workloads across cloud, colocation, edge and on-premises facilities.
“Digital infrastructure operators are still struggling to meet the high standards that customers expect and service level agreements demand – despite improving technologies and the industry’s strong investment in resiliency and downtime prevention,” said Andy Lawrence, founding member and executive director, Uptime Institute Intelligence. The survey resuls will be summarized in a presentation next week.
“The lack of improvement in overall outage rates is partly the result of the immensity of recent investment in digital infrastructure, and all the associated complexity that operators face as they transition to hybrid, distributed architectures,” said Lawrence. “In time, both the technology and operational practices will improve, but at present, outages remain a top concern for customers, investors, and regulators. Operators will be best able to meet the challenge with rigorous staff training and operational procedures to mitigate the human error behind many of these failures.”
About the Author

Rich Miller
Voices of the Industry

