SSD Offload Techniques Unlock AI Scaling with RAG: Increase Query Speed by 50% Using 57% Less Memory? How Can That Be Right?

AI inference with retrieval-augmented generation (RAG) is having a Woodstock moment.
In a similar way to the legendary 1969 Woodstock music festival, inference with RAG is such a powerful and appealing approach to solving business problems that enterprises are rushing to adopt it in droves. Organizers expected about 50,000 attendees at Woodstock, but the lineup was killer—Jimi Hendrix, Janis Joplin, The Who, and dozens of others—and the counterculture vibe so perfectly timed, that the event drew nearly a half-million people to the dairy farm in Bethel, NY. As a result, the experience of many of the attendees was more impacted by food shortages, sanitation problems, and mud than by the music.
When we consider the inference with RAG experience through the Woodstock lens, without sufficient infrastructure in place, the technology’s potential is dampered by poor experience or lack of access altogether.
We need a new approach that enables unprecedented levels of scalability and cost efficiency. Solidigm and Metrum AI have developed a strategy to offload significant amounts of data, including AI model weights and RAG data, from higher-cost memory to high-performance SSDs, unlocking the value of AI like never before.
Download the full white paper, High-Performance TCO-Optimized RAG With SSD Offloading, or if you want to try it yourself, the Github Repo is available here.
What is RAG, and why is it gaining momentum?
Imagine you ask an AI chatbot for guidance on what documents are needed to travel to a foreign country. If there is sufficient correct information present in training data set of the models, you will get a helpful answer.
If there isn’t, one of two things may happen. Either it tells you it doesn’t know, or worse, it confidently gives you a wrong answer. This is called a hallucination, and it’s more common than you might think.
Since the value of AI is tied to the quantity and quality of data available to the model, we use RAG—retrieval-augmented—generation to connect the model to sources of data that were not included in the original training set.
Retrieval-augmented generation retrieves additional relevant data to augment a model’s knowledge before generating a response. It could be an internal corporate database, a news feed, even Wikipedia; almost any source. In our travel query example, we would feed one or more of these sources, and the RAG would grab relevant information before going to the AI model for processing, increasing the likelihood of a good response.
The two major benefits of RAG are:
- Enterprises don’t have to continually retrain models to include more data.
- It enables models to consult information that is more timely, authoritative, and specific than whatever was available in the public training set.
An interesting debate has been heating up around whether RAG is already dead in light of new models that offer huge context windows. Meta’s Llama 4 Scout accommodates 10M tokens. The argument goes that if you can feed that much data into the prompt, you don’t need to connect to external data sources; you can just include all relevant info in the prompt itself.
It’s a reasonable argument, but it may be premature. A March 2025 research paper tested recall (accuracy) of some of these newer models with big context windows. It found that even if a model ostensibly supports context windows in the millions, recall suffered when using more than a fraction, about 2K in most cases.
The problem
You can see why enterprises are embracing RAG-enabled inference. The problem is the same one Woodstock organizers faced more than 50 years ago. More users are demanding more of it in a very sudden way.
Specifically, companies want:
- RAG data sets that are larger to increase both quantity and quality of available data for AI models
- More complex models that can generate high-quality insights as they process the data
Both of these are good goals. But they involve massive amounts of data, which must be stored. In today’s world, model weights and RAG data tend to be stored in memory which can become extremely expensive very quickly.
Introducing the SSD offload approach
Solidigm and Metrum AI have pioneered a new way forward for RAG. The approach utilizes open-source software components, selected and fine-tuned to work together, to move a significant amount of data from memory to SSDs during AI inference.
There are two key components:
- RAG data offload: Using DiskANN, a suite of algorithms for large-scale vector data searches, we are able to relocate part of the RAG data set to SSDs. The ability to scale to much larger data sets in a much more cost-effective way is the primary benefit.
- Model weight offload: Using Ray Serve with the DeepSpeed software suite, we can move a portion of the AI model itself to SSDs. This enables more complex models, or even multiple models, within a fixed GPU memory budget. In one instance we were able to demonstrate the ability to run a 70-billion-parameter model, which typically requires about 160GB of memory, at a reduced peak usage of just 7GB to 8GB.
Key findings
1. Reduced DRAM usage with SSD offloading
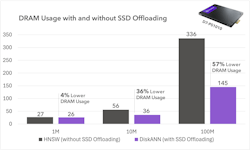
The main value in offloading AI data from memory to SSDs is, naturally, that you need less memory. The approach used VectorDBBench, an open-source benchmarking tool for databases, to measure the effect across three data sets of increasingly bigger size, from 1 million vectors to 100 million.
The magnitude of the benefit scaled with database size. In other words, the more data you’re dealing with, the bigger the memory savings. On the largest data set, a decrease in DRAM usage of 191GB was observed; a 57% decrease. At today’s pricing, that’s a significant cost reduction.
2. Increased query speed with SSD offloading
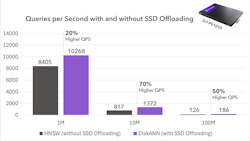
By moving data from memory to SSDs, there was an increase in performance as measured in queries per second (QPS): up to 70% higher on the middle data set, and 50% on the largest one. In other words, not only can you do inference with less memory, but you can also do it faster.
This may strike you as counter-intuitive; when do you ever see a performance increase by reading from storage instead of memory? But we triple-checked the numbers. When configured with default parameters, DiskANN produces higher QPS than HNSW (the conventional in-memory approach). Indexing algorithms with plenty of pre-processing such as Vamana, used by DiskANN, can dramatically speed up similarity searches by efficiently packing the vectors into the SSD (more on indexing in a bit).
It's worth mentioning that in Solidigm testing, HNSW performance could be improved by modifying certain parameters, but at the cost of even higher memory use.
3. The Downside: Increased build time up front
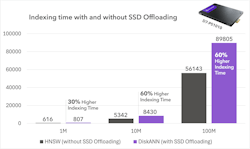
The down side to SSD offloading come in the up front indexing time. The time it takes to build the RAG index is 30% to 60% higher using the offload approach.
However, by more work up front you get better performance on an ongoing basis once the stack is deployed.
For certain use cases, this could mean that RAG is not the right solution. For many others, though, the benefits, in both memory reduction and QPS improvement, will outweigh the increased index build time significantly. Since indexing is an infrequent activity relative to how often you are actually using the model to generate valuable insights, you can reap the benefits of RAG over the lifetime of your model.
4. High recall
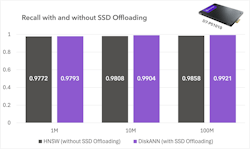
When comparing recall, or how accurate the model outputs are, no significant difference between the conventional and SSD offload approaches were observed. Both of these methods clocked rates near 100%. Essentially, offloading data did not hurt output quality.
Conclusion
When examining the data we measured, we believe there’s significant value in SSD offloading for businesses who want to pull large amounts of data into their inference pipeline without investing in expensive memory. Offloading RAG data means enterprises can scale to bigger data sets at lower costs. Offloading model weights enables companies to deploy solutions on legacy hardware or at the edge, where GPU memory constraints are more severe.
To investigate our claims for yourself, check out the GitHub repo. You’ll find everything you need to reproduce these results yourself. You can also dig into the data and methodology in greater detail in the white paper; High-Performance TCO-Optimized RAG With SSD Offloading.
About the Author

Ace Stryker
Ace Stryker is the director of market development at Solidigm, where he focuses on emerging applications for the company’s portfolio of data center storage solutions.
Voices of the Industry

